Hive: SQL-like Data Warehousing on Hadoop
by Pradyuman
Hive transforms the complex world of distributed data processing into a familiar SQL-like environment. This paper explores the core components and mechanisms that make Hive an efficient data warehouse solution built on Hadoop.
Data Model
Hive’s architecture revolves around a three-tiered data model that elegantly balances flexibility with performance:
Tables
Tables form the primary organizational unit in Hive, each mapped to a dedicated HDFS directory. Unlike traditional databases, Hive tables can handle both structured and semi-structured data through SerDes (Serializer/Deserializer) interfaces.
Partitions
Partitioning enables horizontal data slicing based on column values. Each partition creates a subdirectory under the table directory, allowing Hive to skip irrelevant data blocks during query execution. For instance, a sales table partitioned by date would create distinct paths like /sales/date=2024-01-01/.
Buckets
Within partitions, data gets distributed across multiple files through bucketing. Hive applies a hash function on specified columns to determine bucket placement. This mechanism enhances join performance and enables efficient sampling operations.
The directory structure looks like this:
warehouse/
└── table_name/
└── partition_column=value/
└── bucket_N.file
Query Language
HiveQL, Hive’s native query language, closely resembles traditional SQL while adding distributed computing capabilities. At the time of writing, it supported:
- SELECT, PROJECT, JOIN operations
- Aggregations and UNION ALL
- Subqueries in FROM clauses
- Multi-table inserts with shared input scanning optimization
Architecture
Hive’s architecture consists of four main components:
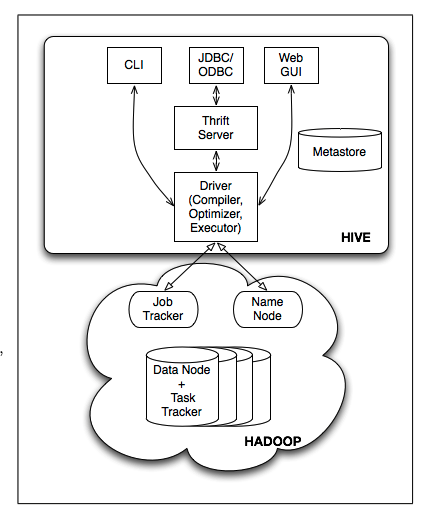
External Interfaces
Multiple interfaces provide access to Hive:
- Command Line Interface (CLI)
- Web UI
- JDBC/ODBC drivers for application integration
Thrift Server
A cross-language service framework that exposes a simple API for executing HiveQL statements, enabling clients written in different programming languages to interact with Hive.
Metastore
The system catalog stores essential metadata about Hive tables, including::
- Databases (namespaces for tables)
- Table Metadata (columns, types, owner, storage, SerDe information)
- Partition specifications
Driver
Manages query execution through a four-step process:
- Parsing -> Simply converts HiveQL text to a tree stucture.
- Semantic Analyzer -> Validates and enriches the parse tree by checking schema, types, and resolving names/references.
- Logical Plan Generator -> Transforms the validated query into a tree of logical operators that represent the computation steps.
- Optimizer -> Rewrites the logical plan to improve efficiency through join combinations, repartitioning, and predicate/column management.
Conclusion
The key takeaway from studying Hive was seeing how a SQL query transforms into actual execution steps. When we write a SQL query, Hive first converts it into a tree structure, then checks if everything in the query makes sense (like if tables and columns exist), creates a plan of what needs to be done, and finally makes that plan better by optimizing things like joins and filters. This helped me understand what really happens behind the scenes when we run queries, not just in Hive but in other database systems too.
tags: query - big-data