Inside MapReduce: The Engine That Powers Large-Scale Data Processing
by Pradyuman
MapReduce consists of two main components: Map, which converts input data into (key,value) pairs using user-defined functions, and a Reduce function. While this might sound like a simple program, it handles many complex tasks associated with distributed computing, hiding them from the end user and letting them focus on core logic. The system can handle petabytes of data while abstracting details like parallelization, fault-tolerance, data distribution, and load balancing.
System Overview
The system runs on clusters of hundreds of machines and can be easily configured using a MapReduce specification object. It operates with one master node and several worker nodes, responsible for map or reduce tasks.
Example Applications
Here are some common use cases of MapReduce:
Reverse Weblink Graph
- Map: outputs
(target, source) - Reduce: outputs
(target, [source])
URL Access Frequency
- Map: outputs
(url, 1) - Reduce: outputs
(url, total_count)
Distributed Grep
- Map: outputs
(word, line) - Reduce: identity function
Inverted Index
- Map: outputs
(word, documentID) - Reduce: outputs
(word, [documentID])
Implementation Details
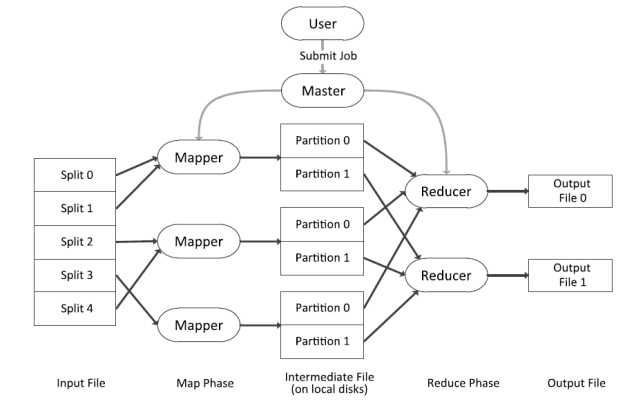
Initial Setup
- Input data is first split into M pieces, corresponding to M map tasks
- Each piece of this input makes up one Map task
- Master node starts assigning these tasks to worker nodes one by one
Map Phase
- Worker reads the input, parses key/value pairs from this data, passes them to user-defined map function, gets intermediate keys from this function and buffers them in memory
- Periodically this buffer is written into local disk as a spill file
- Data is split into R partitions, each corresponding to a reduce task
Reduce Phase
- Location of these pairs are passed back to master node which passes this on to reduce workers
- Reduce worker uses RPC to read the buffer data from local disk of map workers
- Once reduce worker reads all data, it sorts these intermediate keys, using external sort if data is too large to fit in memory
- It iterates over sorted intermediate data, passing each unique key’s corresponding set of intermediate values to the reduce function
- Output is appended to a final output file for this reduce partition
Fault Tolerance
Worker Failure
Master pings worker periodically, if no response is received from a worker for certain amount of time it is marked as failed. The system handles worker failures in the following ways:
- Map tasks completed or in-progress by failed worker are reset back to idle state
- These tasks become eligible to be rescheduled on other workers
- Reduce tasks that have already read data from failed map task need to re-read it from new worker
- Reduce tasks don’t need to be re-executed since output is stored in global file system
Master Failure
The system handles master node failures through checkpointing:
- Master periodically writes checkpoint of master data structures
- On failure of master node, a new copy can be started from last checkpoint state
Performance Optimizations
Task Granularity
The system divides work into configurable pieces:
- Map phase is subdivided into M pieces
- Reduce phase is divided into R pieces
- Master must make O(M+R) scheduling decisions
- Master keeps O(M*R) state in memory
Note: R is often constrained by user because the output of each reduce task ends up in a separate output file. M is typically chosen so that individual tasks have roughly 16-64 MB of input data.
Backup Tasks
The system includes mechanisms to handle stragglers (slow-performing machines):
- A “straggler” is a machine that takes unusually long time to complete one of the last map or reduce tasks
- Stragglers can occur due to various reasons like bad disks or resource competition
- When the program is near completion, master schedules backup execution of remaining in-progress tasks
- Task is marked as complete whenever either primary or backup execution finishes
- This optimization significantly reduces execution time in large MapReduce operations
Refinements
While the basic functionality provided by map and reduce functions is sufficient for most use cases, MapReduce includes several useful extensions to handle specific scenarios and optimize performance.
Partitioning Function
The default partitioning mechanism in MapReduce uses a simple hash function (hash(key) mod R) to partition data for reduce functions and output files. However, this approach isn’t always optimal for all data types. For instance, when working with URLs as output keys, you might want all URLs from the same host to end up in the same partition. To address such scenarios, users can provide a custom partitioning function that better suits their specific data distribution needs.
Combiner Function
When Map tasks produce large amounts of output data, network transfer can become a bottleneck. To address this, MapReduce provides a combining feature through which users can specify a combiner function. This function runs on the same worker node as the Map task after the task completes. It combines duplicate data before sending it to the Reduce tasks, significantly reducing the amount of data that needs to be transferred over the network. The output from this combining step is then fed to the Reduce tasks, improving overall performance.
Skipping Bad Records
In large-scale data processing, encountering bad records is almost inevitable. MapReduce addresses this challenge by providing an optional execution mode that can detect and handle faulty records gracefully. This functionality is implemented using signal handlers in worker nodes that inform the master about problematic records. When the master receives such notifications, it maintains a list of bad records and ensures they’re skipped during any re-execution of the map tasks, allowing the overall computation to proceed smoothly despite data imperfections.
Status Information
MapReduce includes a built-in monitoring system through an internal HTTP server run by the master node. This server exports a set of status pages designed for human consumption, providing valuable insights into the computation’s progress. Users can access links to the standard error and standard output files generated by each task, helping with debugging and monitoring. The top-level status page serves as a central dashboard, displaying information about any worker failures and identifying which map and reduce tasks were running on failed workers at the time of failure. This comprehensive monitoring system helps operators quickly identify and respond to any issues that arise during execution.
Conclusion
MapReduce’s elegance lies in its ability to handle massive-scale data processing while keeping the programming model simple. By automating parallelization, fault tolerance, and data distribution, it lets developers focus solely on their computational logic. These core principles continue to influence modern distributed systems, making MapReduce a foundational model in distributed computing.
tags: engineering-systems - big-data